Act2Answer
Does VLA Even Know the Basics? Measuring Commonsense and World Knowledge Retention in Vision-Language-Action Models
Abstract
Embodied Vision-Language-Action (VLA) models are typically obtained by fine-tuning powerful pretrained VLMs on robotics data, yet it is unclear how much commonsense and factual knowledge they retain after adaptation. Failures on knowledge-sensitive tasks are ambiguous, conflating missing knowledge with poor generalization of low-level control. We introduce Act2Answer, a lightweight protocol that adapts VLM knowledge benchmarks to VLA evaluation by requiring agents to answer through action. Each question becomes a short tabletop episode where the agent performs a single object-placement action to select among candidate answers, yielding an action-grounded success rate with reduced control confounds. We curate a test suite of such environments across diverse commonsense and world-knowledge categories and introduce layerwise intent probing to localize answer-relevant information across the VLM backbone and action head. In a large-scale study of 7 VLA models and 9 VLM baselines, we systematically rank models across categories, finding that VLAs show solid performance on simple concepts while exhibiting larger gaps on richer semantic categories relative to their source VLMs, that VQA co-training is associated with better knowledge retention, and that answer-relevant signals peak in middle VLA layers but attenuate in upper layers.
The Act2Answer Protocol
VLA evaluation is usually task-success centric: if a policy fails, it is difficult to know whether the problem came from perception, low-level control, the environment, or missing knowledge. Because the same success rate can arise from very different causes, end-to-end task success is rarely diagnostic of what a VLA actually knows. Act2Answer isolates a sharper question: can the model use relevant commonsense or world knowledge to choose an action?
Instead of asking a model to decode a textual answer, each VLM benchmark question is converted into a short tabletop episode. The agent sees two visual answer options and must move a cube onto the correct answer plate. This keeps the setting embodied while deliberately reducing motor complexity and long-horizon control confounds, so the outcome is more directly informative about retained knowledge.

Example Act2Answer episodes, built on top of VLM benchmark questions. In each episode, the embodied agent must interpret a natural-language instruction and control the robot arm to move the cube onto the correct answer plate.
Benchmark Construction
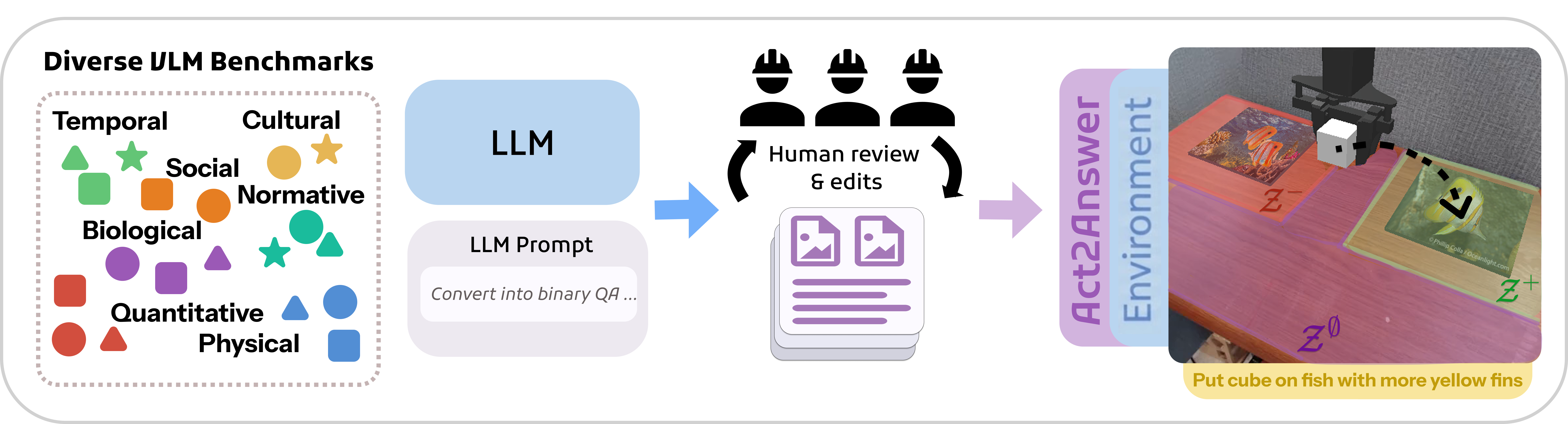
Data curation pipeline. Act2Answer selects tasks matching the target categories, filters and normalizes them for instruction length and visual legibility, converts open-ended or multiple-choice items into binary decisions, and wraps each one into an embodied environment with consistent answer placement.
Rather than authoring new questions from scratch, Act2Answer adapts five established, community-validated VLM benchmarks into a single embodied interface. Each source contributes the knowledge domains it covers best, grounding our evaluation in already-validated material while testing whether the same distinctions survive the transfer from VLM to VLA.
Hover (or tap) a domain in the wheel to reveal its source benchmarks and per-category curation counts.
Per-category curation statistics. The full suite covers 12 categories with 1,720 unique binary-choice items, corresponding to 3,440 evaluation episodes once both the original and swapped left/right configurations are included. Final Eval counts episodes after swapping; for VL-Think, Initial Pool reports the number of source concepts rather than raw images.
Main Results
Results across all knowledge-sensitive categories. VLA models (bottom) answer by embodied action selection under Act2Answer; VLM baselines (top) use an action-free text probe as an upper-bound reference. Cell color encodes success rate from below chance to strong; bold marks the best score in a column within each block.
| Model | Social | Physical | Quant. | Temporal | Normative | Cultural | Biological | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Emotion | Attribute | State | Color | Shape | Symmetry | Counting | Time | Public Info | Traffic | Celebrity | Living World | |
| Vision-Language Models — action-free text probe | ||||||||||||
| InternVL3.5-8B | 95% | 68% | 64% | 100% | 89% | 69% | 52% | 99% | 85% | 75% | 99% | 91% |
| InternVL3.5-38B | 99% | 73% | 68% | 100% | 96% | 83% | 59% | 100% | 94% | 81% | 100% | 96% |
| Ovis2.5-9B | 89% | 69% | 69% | 100% | 98% | 83% | 59% | 99% | 88% | 85% | 100% | 97% |
| Qwen2.5-7B | 89% | 64% | 68% | 100% | 90% | 78% | 62% | 99% | 80% | 86% | 100% | 94% |
| Qwen2.5-32B | 99% | 69% | 69% | 100% | 93% | 83% | 61% | 99% | 85% | 86% | 100% | 96% |
| Qwen3-8B | 86% | 68% | 67% | 100% | 97% | 81% | 65% | 98% | 83% | 93% | 100% | 95% |
| Qwen3-32B | 92% | 67% | 66% | 100% | 98% | 83% | 59% | 100% | 87% | 90% | 100% | 86% |
| Prismatic-VLM-7B | 82% | 59% | 61% | 96% | 85% | 67% | 52% | 96% | 75% | 76% | 99% | 82% |
| PaliGemma-3B | 53% | 50% | 52% | 47% | 48% | 49% | 49% | 51% | 48% | 49% | 48% | 49% |
| Vision-Language-Action Models — embodied action selection (Act2Answer) | ||||||||||||
| OpenVLA | 48% | 51% | 49% | 89% | 64% | 45% | 48% | 49% | 49% | 46% | 50% | 52% |
| OpenVLA (SFT) | 41% | 45% | 44% | 82% | 53% | 38% | 46% | 37% | 47% | 46% | 42% | 45% |
| OpenVLA (RL) | 46% | 50% | 47% | 88% | 61% | 44% | 50% | 48% | 46% | 48% | 47% | 52% |
| SpatialVLA | 47% | 48% | 50% | 87% | 83% | 45% | 52% | 46% | 51% | 57% | 55% | 49% |
| π0 | 51% | 50% | 48% | 86% | 49% | 46% | 50% | 48% | 46% | 48% | 38% | 45% |
| Magma | 72% | 63% | 59% | 89% | 81% | 37% | 51% | 77% | 88% | 80% | 94% | 77% |
| Xiaomi-Robotics-R0 | 63% | 52% | 50% | 91% | 82% | 58% | 48% | 52% | 64% | 57% | 68% | 56% |
| InternVLA-M1 | 53% | 49% | 53% | 90% | 66% | 43% | 48% | 49% | 54% | 53% | 52% | 58% |
Main Act2Answer results. OpenVLA (SFT) and OpenVLA (RL) are downstream fine-tuning ablations of OpenVLA on a small pick-and-place dataset.
RQ1 · Simple primitives
Nearly all VLAs solve basic perceptual tasks such as Color and Shape with high success, so simple visual distinctions remain behaviorally accessible. π0 is a notable exception on Shape, where it sits near chance.
RQ2 · Richer semantics
On non-primitive categories most VLAs hover at or near chance, with Magma the clear exception. No evaluated VLA exceeds chance on Symmetry or Counting — these stay uniformly hard.
RQ3 · The VLM–VLA gap
Compared to their source VLMs under an action-free probe, VLAs drop by roughly 20–40 points across most domains — evidence of a marked decline in knowledge-sensitive performance after embodied adaptation.
Layerwise Intent Probing
Beyond task success, Act2Answer measures whether answer-relevant information is linearly recoverable from internal VLA representations. A linear probe trained at each layer predicts the correct answer option, helping localize whether knowledge remains in the backbone and whether it survives into the action pathway.
Prefix labels indicate representations from the VLM component, while Action labels indicate representations from the action component. Answer-relevant signals often peak in intermediate layers and attenuate toward the later action layers used for prediction.
| Model | Prefix | Action | Retention |
|---|---|---|---|
| Magma | 75.23 | 72.60 | 0.8702 |
| Xiaomi-Robotics-R0 | 68.04 | 64.98 | 0.8159 |
| SpatialVLA | 65.70 | 62.60 | 0.7808 |
| OpenVLA | 68.71 | 64.61 | 0.7697 |
| SmolVLA | 63.18 | 57.73 | 0.5809 |
| π0 | 64.99 | 55.40 | 0.3620 |
Averaged probing-based retention by model. Prefix and Action report the maximum probing accuracy over backbone and action-part layers; Retention is the chance-normalized ratio of the strongest above-chance signal in the action expert to that in the backbone.
Key takeaways
- Where does the knowledge go? (RQ4) Intermediate backbone layers are often above chance, yet probe accuracy declines toward the final action layers — a bottleneck where answer-relevant information is present internally but is not reliably translated into the correct action.
- Does vision-language supervision help? (RQ5) Models trained with joint vision-language and robotics supervision (Magma, Xiaomi-Robotics-R0, InternVLA-M1) outperform robotics-only policies (OpenVLA, SpatialVLA, π0) on most knowledge-sensitive categories.
- Does downstream fine-tuning help? (RQ6) Additional SFT/RL on OpenVLA does not consistently improve knowledge-sensitive performance and can hurt it — State and Color drop noticeably after SFT.
Additional Examples

Social, cultural, and biological categories. Emotion, celebrity, and living-world examples.

Temporal and normative categories. Time, traffic, and public-information examples.
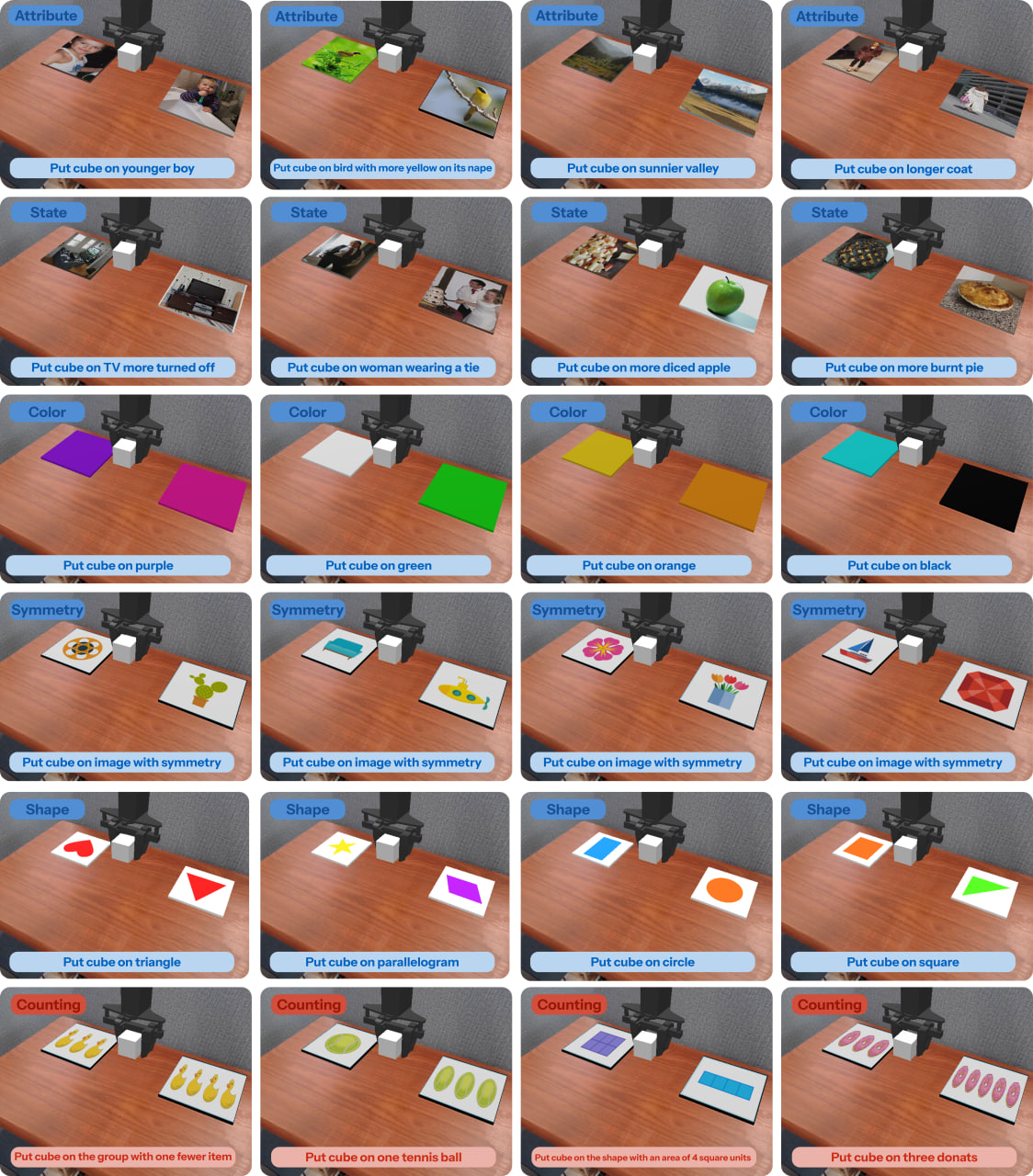
Physical and quantitative categories. Attribute, state, color, symmetry, shape, and counting examples.
BibTeX
@misc{kachaev2026doesvlaknowbasics,
title={Does VLA Even Know the Basics? Measuring Commonsense and World Knowledge Retention in Vision-Language-Action Models},
author={Nikita Kachaev and Andrey Moskalenko and Matvey Skripkin and Nikita Kurlaev and Daria Pugacheva and Albina Burlova and Mikhail Kolosov and Denis Shepelev and Andrey Kuznetsov and Elena Tutubalina and Aleksandr I. Panov and Alexey K. Kovalev and Vlad Shakhuro},
year={2026},
eprint={2606.19297},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2606.19297},
}